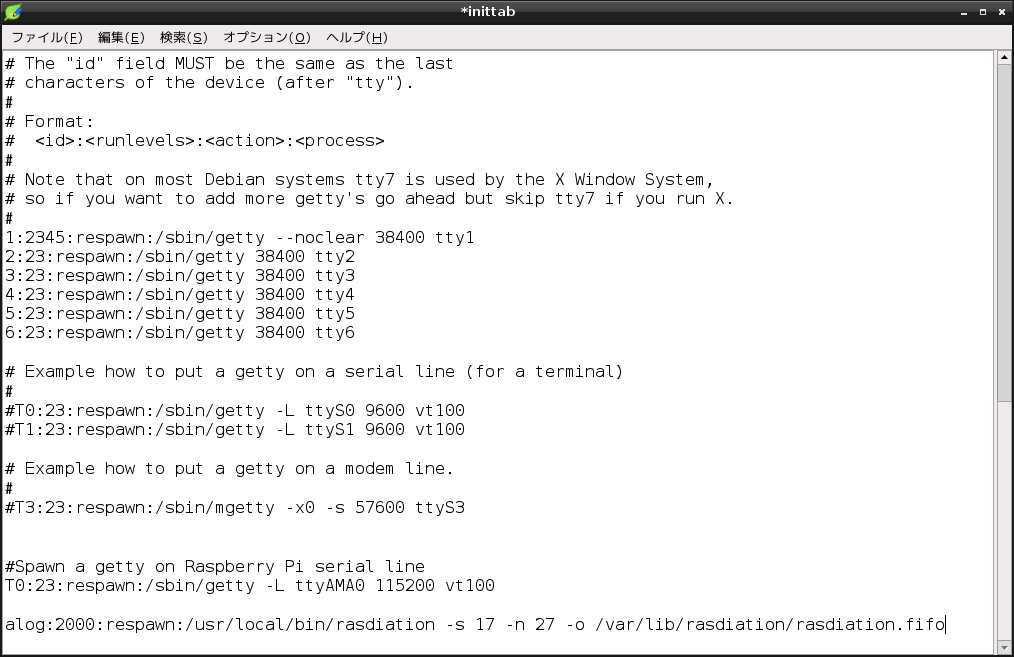
アカウントがプライベート設定のフォロワーがいると403 forbiddenになって処理が止まるようなので一応対策しました
手動で実行することで対象のID(数字)を確認出来ます
#!/usr/bin/perl
use utf8;
use strict;
use warnings;
# モジュール使用宣言
use Array::Diff;
use Net::Twitter::Lite::WithAPIv1_1;
use YAML::Tiny;
use Encode;
use FindBin;
# 現在のパスから見て設定ファイルを読み込み
my $config = (YAML::Tiny->read($FindBin::Bin . '/config.yml'))->[0];
# OAuth認証
my $twitter = Net::Twitter::Lite::WithAPIv1_1->new(
traits => ['API::REST', 'OAuth'],
consumer_key => $config->{'consumer_key'},
consumer_secret => $config->{'consumer_secret'}
);
$twitter->access_token($config->{'access_token'});
$twitter->access_token_secret($config->{'access_token_secret'});
# 認証失敗時の処理
die('Auth failed:'.$config->{'username'}) unless ( $twitter->authorized ) ;
# ユーザー名を含むユーザー情報を取得
my $own_id = $twitter->verify_credentials->{id};
my $nextc = -1; # paging default.
my @following_id_list; # outgo
# APIの仕様?から一度に100人までしか取得できないから0が返ってくるまでdoブロックをループ
do{
# パラメータcursorは前回取得したフォローイングまでの番号が入っている
my $following_list = $twitter->friends_ids({ id=>$own_id, cursor => $nextc });
$nextc = $following_list->{next_cursor};
# 配列からフォローイングのidを取得
foreach my $id (@{ $following_list->{ids} }){
push(@following_id_list, $id); # 後で比較するためにフォローイングを配列に保管
}
}while($nextc!=0);
# 文字昇順でソート
@following_id_list = sort @following_id_list;
$nextc = -1;
my @followers_id_list; # income
# APIの仕様?から一度に100人までしか取得できないから0が返ってくるまでdoブロックをループ
do{
# パラメータcursorは前回取得したフォロワーまでの番号が入っている
my $followers_list = $twitter->followers_ids({ id=>$own_id, cursor => $nextc });
$nextc = $followers_list->{next_cursor};
# 配列からフォロワーのidを取得
foreach my $id (@{ $followers_list->{ids} }){
push(@followers_id_list, $id); # 後で比較するためにフォロワーを配列に保管
}
}while($nextc!=0);
# 文字昇順でソート
@followers_id_list = sort @followers_id_list;
# 差分を取得(フォローイング)
my $diff_following = Array::Diff->diff(\@following_id_list, \@followers_id_list);
# 差分を取得(フォロワー)
my $diff_followers = Array::Diff->diff(\@followers_id_list, \@following_id_list);
# リムった人をリム返し
foreach my $delid_following (@{ $diff_following->{deleted} }){
eval{$twitter->destroy_friend({user_id => $delid_following})};
# プライベートだとエラーになる人がいるので確認用
print $delid_following . "\n" if($@);
}
# フォローした人をフォロー返し
foreach my $delid_followers (@{ $diff_followers->{deleted} }){
eval{$twitter->create_friend({user_id => $delid_followers})};
# プライベートだとエラーになる人がいるので確認用
print $delid_followers . "\n" if($@);
}
![IMG_1589[1]](https://www.orsx.net/wp-content/uploads/2013/03/IMG_15891.jpg)
![IMG_1620[1]](https://www.orsx.net/wp-content/uploads/2013/03/IMG_16201.jpg)
![IMG_1621[1]](https://www.orsx.net/wp-content/uploads/2013/03/IMG_16211.jpg)
![IMG_1622[1]](https://www.orsx.net/wp-content/uploads/2013/03/IMG_16221.jpg)
![IMG_1623[1]](https://www.orsx.net/wp-content/uploads/2013/03/IMG_16231.jpg)
![IMG_1625[1]](https://www.orsx.net/wp-content/uploads/2013/03/IMG_16251.jpg)
![IMG_1627[1]](https://www.orsx.net/wp-content/uploads/2013/03/IMG_16271.jpg)

最近のコメント